Introduction
The Job Service facilitates the scheduled execution of tasks in a cloud environment. These tasks are implemented by independent services, and can be started by using any of the Job Service supported interaction modes, based on Http calls or Knative Events delivery.
To schedule task execution, you must create a Job configured with the following information:
-
Schedule: the job triggering periodicity. -
Recipient: the entity that is called on the job execution for the given interaction mode, and receives the execution parameters.
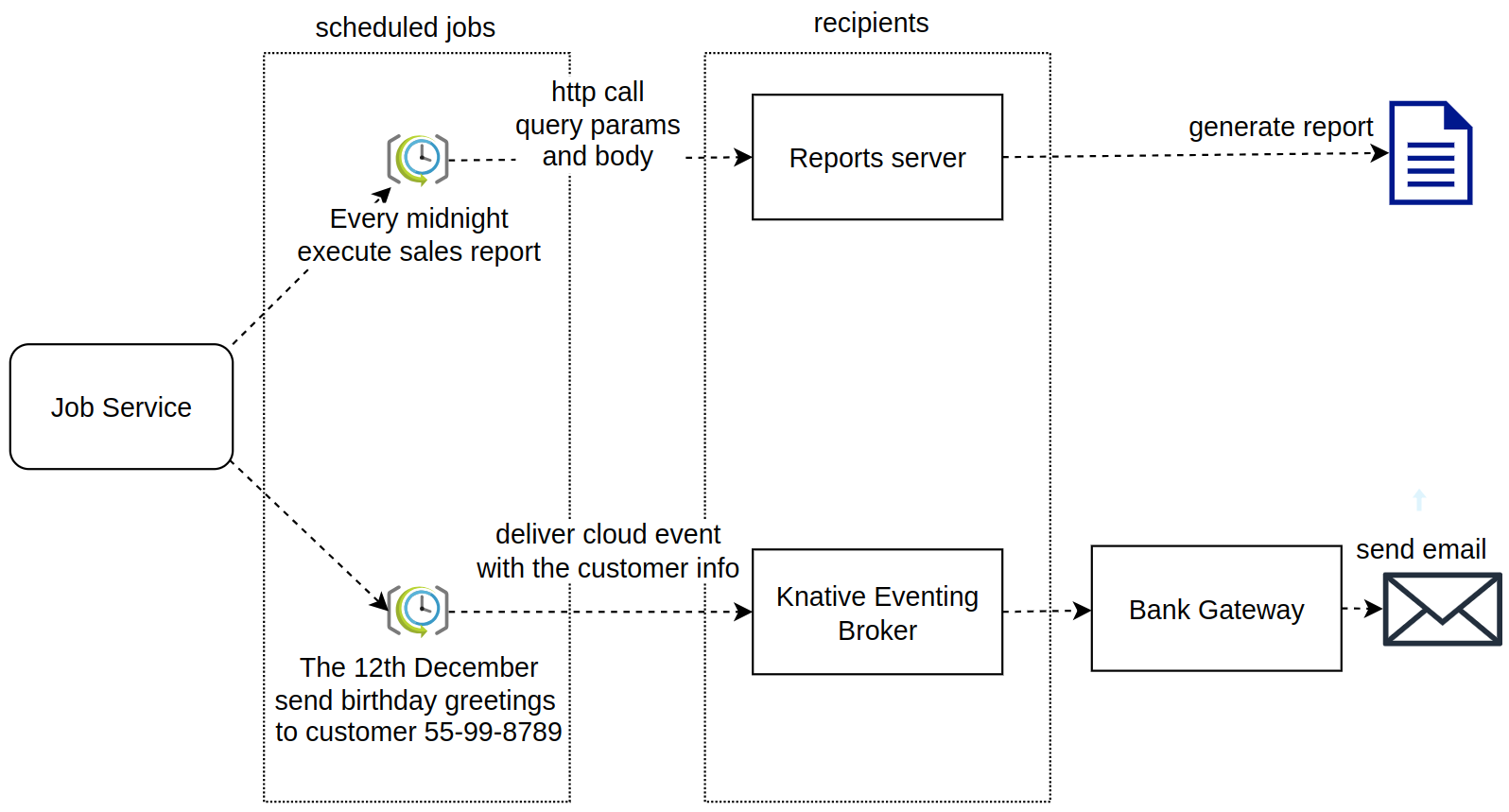
Integration with the Workflows
In the context of the SonataFlow, the Job Service is responsible for controlling the execution of the time-triggered actions. And thus, all the time-based states that you can use in a workflow, are handled by the interaction between the workflow and the Job Service.
For example, every time the workflow execution reaches a state with a configured timeout, a corresponding job is created in the Job Service, and when the timeout is met, a http callback is executed to notify the workflow.
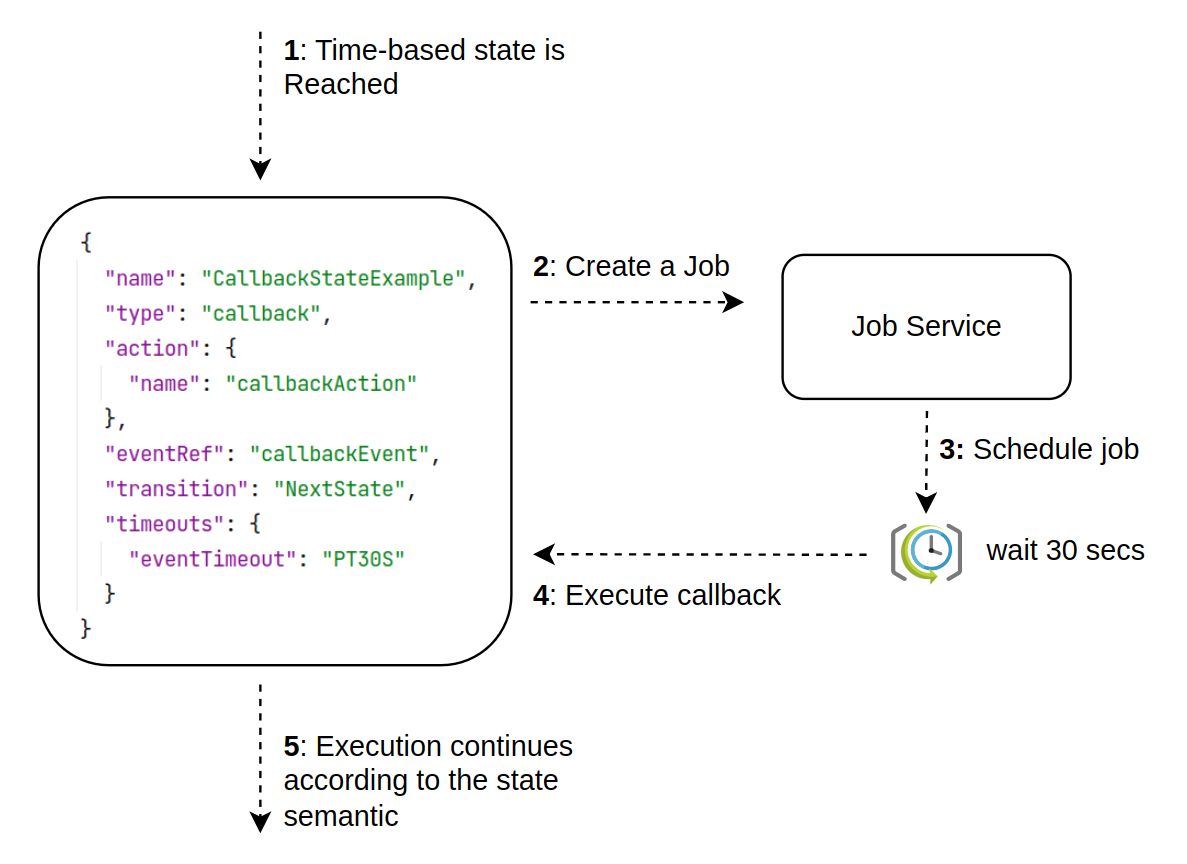
To set up this integration you can use different communication alternatives, that must be configured by combining the Job Service and the Quarkus Workflow Project configurations. Alternatively, when you work with SonataFlow Operator workflow deployments, the operator can manage all these configurations.
|
If the project is not configured to use the Job Service, all time-based actions will use an in-memory implementation of that service. However, this setup must not be used in production, since every time the application is restarted, all the timers are lost, making it unsuitable for serverless architectures where applications might scale to zero at any time, etc. |
|
If you are working with the SonataFlow Operator be sure that you read this section SonataFlow Operator managed deployments. |
Jobs life-span
Since the main goal of the Job Service is to work with the active jobs, such as the scheduled jobs that needs to be executed, when a job reaches a final state, it is removed from the Job Service. However, in some cases where you want to keep the information about the jobs in a permanent repository, you can configure the Job Service to produce status change events, that can be collected by the Data Index Service, where they can be indexed and made available by GraphQL queries.
SonataFlow Operator managed deployment
When you work with the SonataFlow Operator to deploy your workflows, there’s no need to do any manual Job Service installation or configuration, the operator already has the ability to do that. Additionally, it can manage all the required configurations for every workflow to connect with it.
To learn how to install and configure the Job Service in this case, you must read the Operator Supporting Services section.
Custom Execution
To execute the Job Service in your docker or Kubernetes environment, you must use any of the following images, depending on the persistence mechanism to use PostgreSQL or Ephemeral.
-
docker.io/apache/incubator-kie-kogito-jobs-service-postgresql -
docker.io/apache/incubator-kie-kogito-jobs-ephemeral
In the next topics you can see how to configure them.
|
The common configurations and the eventing API configurations are the same for both images. |
We recommend that you follow this procedure:
-
Identify the image to use depending on the persistence mechanism, and see the required configuration parameters specific for that image.
-
Identify if the Eventing API is required for your needs and see the required configuration parameters.
-
Identify if the project containing your workflows is configured with the appropriate Job Service Quarkus Extension.
Finally, when you run the image, you must pass these configurations using environment variables or using system properties with java like names.
Using environment variables
To configure the image by using environment variables you must pass one environment variable per each parameter.
docker run -it -e QUARKUS_DATASOURCE_USERNAME=postgres -e VARIABLE_NAME=value docker.io/apache/incubator-kie-kogito-jobs-service-postgresql:latestspec:
containers:
- name: jobs-service-postgresql
image: docker.io/apache/incubator-kie-kogito-jobs-service-postgresql:latest
imagePullPolicy: Always
ports:
- containerPort: 8080
name: http
protocol: TCP
env:
# Set the image parameters as environment variables in the container definition.
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: QUARKUS_DATASOURCE_USERNAME
value: postgres
- name: QUARKUS_DATASOURCE_PASSWORD
value: pass
- name: QUARKUS_DATASOURCE_JDBC_URL
value: jdbc:postgresql://timeouts-showcase-database:5432/postgres?currentSchema=jobs-service
- name: QUARKUS_DATASOURCE_REACTIVE_URL
value: postgresql://timeouts-showcase-database:5432/postgres?search_path=jobs-service|
This is the recommended approach when you execute the Job Service in Kubernetes. The timeouts showcase example Quarkus Workflow Project with standalone services contains an example of this configuration, see. On the other hand, when you work with the SonataFlow Operator, it can automatically manage all these configurations, see. |
Using system properties with java like names
To configure the image by using system properties you must pass one property per parameter, however, in this case, all these properties are passed as part of a single environment with the name JAVA_OPTIONS.
docker run -it -e JAVA_OPTIONS='-Dquarkus.datasource.username=postgres -Dmy.sys.prop1=value1 -Dmy.sys.prop2=value2' \
docker.io/apache/incubator-kie-kogito-jobs-service-postgresql:latest|
I case that you need to convert a java like property name, to the corresponding environment variable name, to use the environment variables configuration alternative, you must apply the naming convention defined in the Quarkus Configuration Reference.
For example, the name |
Common configurations
Common configurations that affect the job execution retries, startup procedure, etc.
| Name | Description | Default |
|---|---|---|
|
A long value that defines the retry back-off time in milliseconds between job execution attempts, in case the execution fails. |
|
|
A long value that defines the maximum interval in milliseconds when retrying to execute jobs, in case the execution fails. |
|
| Name | Description | Default |
|---|---|---|
|
A long value that defines the retry back-off time in milliseconds between job execution attempts, in case the execution fails. |
|
|
A long value that defines the maximum interval in milliseconds when retrying to execute jobs, in case the execution fails. |
|
Job Service PostgreSQL Configuration
PostgreSQL is the recommended database to use with the Job Service. Additionally, it provides an initialization procedure that integrates Flyway for the database initialization. Which automatically controls the database schema, in this way, the tables are created or updated by the service when required.
In case you need to externally control the database schema, you can check and apply the DDL scripts for the Job Service in the same way as described in Manually executing scripts guide.
To configure the Job Service PostgreSQL you must provide these configurations:
| Variable | Description | Example value |
|---|---|---|
|
Username to connect to the database. |
|
|
Password to connect to the database |
|
|
JDBC datasource url used by Flyway to connect to the database. |
|
|
Reactive datasource url used by the Job Service to connect to the database. |
|
| Variable | Description | Example value |
|---|---|---|
|
Username to connect to the database. |
|
|
Password to connect to the database |
|
|
JDBC datasource url used by Flyway to connect to the database. |
|
|
Reactive datasource url used by the Job Service to connect to the database. |
|
The timeouts showcase example Quarkus Workflow Project with standalone services, shows how to run a PostgreSQL based Job Service as a Kubernetes deployment. In your local environment you might have to change some of these values to point to your own PostgreSQL database.
Job Service Ephemeral Configuration
The Ephemeral persistence mechanism is based on an embedded PostgreSQL database and does not require any specific configuration other thant the common configurations and the Eventing API.
|
The database is recreated on each service restart, and thus, it must be used only for testing purposes. |
Eventing API
The Job Service provides a Cloud Event based API that can be used to create and delete jobs. This API is useful in deployment scenarios where you want to use an event based communication from the workflow runtime to the Job Service. For the transport of these events you can use the Knative eventing system or the kafka messaging system.
Knative eventing
By default, the Job Service Eventing API is prepared to work in a Knative eventing system. This means that by adding no additional configurations parameters, it’ll be able to receive cloud events via the Knative eventing system to manage the jobs. However, you must still prepare your Knative eventing environment to ensure these events are properly delivered to the Job Service, see Knative eventing supporting resources.
Finally, the only configuration parameter that you must set, when needed, is to enable the propagation of the Job Status Change events, for example, if you want to register these events in the Data Index Service.
| Variable | Description | Default value |
|---|---|---|
|
|
|
| Variable | Description | Default value |
|---|---|---|
|
|
|
Knative eventing supporting resources
To ensure the Job Service receives the Knative events to manage the jobs, you must create the create job events and delete job events triggers shown in the diagram below. Additionally, if you have enabled the Job Status Change events propagation you must create the sink binding.
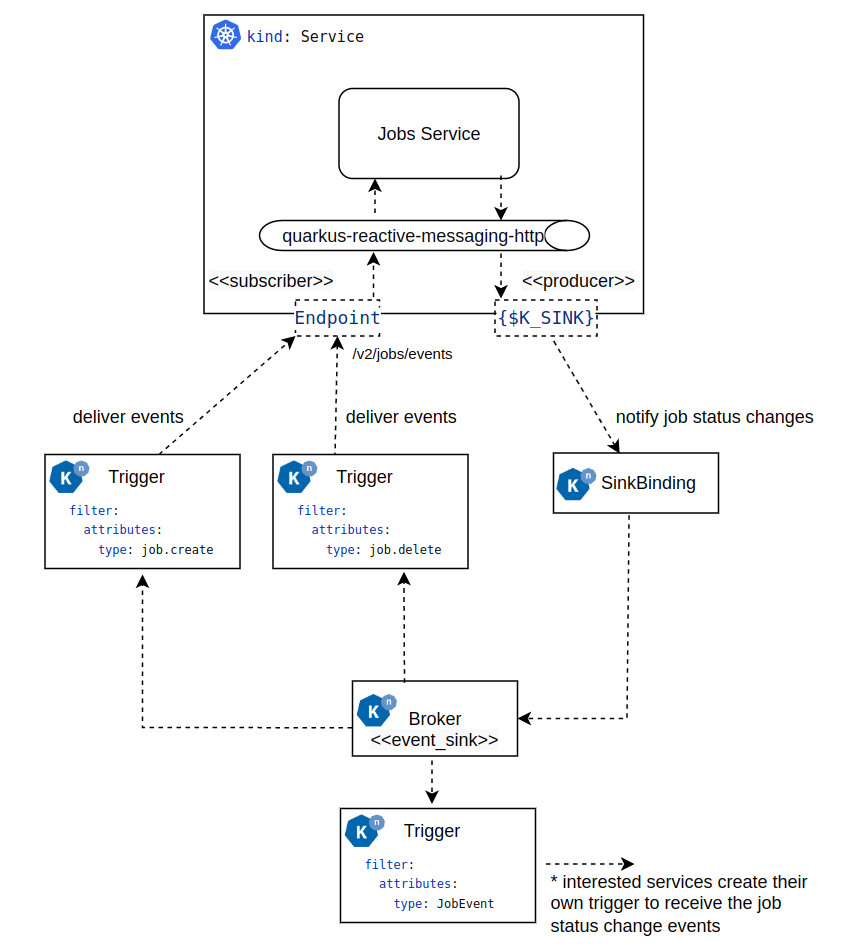
The following snippets shows an example on how you can configure these resources. Consider that these configurations might need to be adjusted to your local kubernetes cluster.
|
We recommend that you visit this example Quarkus Workflow Project with standalone services to see a full setup of all these configurations. |
apiVersion: eventing.knative.dev/v1
kind: Trigger
metadata:
name: jobs-service-postgresql-create-job-trigger
spec:
broker: default
filter:
attributes:
type: job.create
subscriber:
ref:
apiVersion: v1
kind: Service
name: jobs-service-postgresql
uri: /v2/jobs/eventsapiVersion: eventing.knative.dev/v1
kind: Trigger
metadata:
name: jobs-service-postgresql-delete-job-trigger
spec:
broker: default
filter:
attributes:
type: job.delete
subscriber:
ref:
apiVersion: v1
kind: Service
name: jobs-service-postgresql
uri: /v2/jobs/eventsFor more information about triggers, see Knative Triggers.
apiVersion: sources.knative.dev/v1
kind: SinkBinding
metadata:
name: jobs-service-postgresql-sb
spec:
sink:
ref:
apiVersion: eventing.knative.dev/v1
kind: Broker
name: default
subject:
apiVersion: apps/v1
kind: Deployment
selector:
matchLabels:
app.kubernetes.io/name: jobs-service-postgresql
app.kubernetes.io/version: 2.0.0-SNAPSHOTFor more information about sink bindings, see Knative Sink Bindings.
Kafka messaging
To enable the Job Service Eventing API via the Kafka messaging system you must provide these configurations:
| Variable | Description | Default value |
|---|---|---|
|
Set the quarkus profile with the value |
By default, the kafka eventing api is disabled. |
|
|
|
|
A comma-separated list of host:port to use for establishing the initial connection to the Kafka cluster. |
|
|
Kafka topic for events API incoming events. In general you don’t need to change this value. |
|
|
Kafka topic for job status change outgoing events. In general you don’t need to change this value. |
|
| Variable | Description | Default value |
|---|---|---|
quarkus.profile |
Set the quarkus profile with the value |
By default, the kafka eventing api is disabled. |
|
|
|
|
A comma-separated list of host:port to use for establishing the initial connection to the Kafka cluster. |
|
|
Kafka topic for events API incoming events. In general you don’t need to change this value. |
|
|
Kafka topic for job status change outgoing events. In general you don’t need to change this value. |
|
|
Depending on your Kafka messaging system configuration you might need to apply additional Kafka configurations to connect to the Kafka broker, etc. To see the list of all the supported configurations you must read the Quarkus Apache Kafka Reference Guide. |
Leader election
Currently, the Job Service is a singleton service, and thus, just one active instance of the service can be scheduling and executing the jobs.
To avoid issues when it is deployed in the cloud, where it is common to eventually have more than one instance deployed, the Job Service supports a leader instance election process. Only the instance that becomes the leader activates the external communication to receive and schedule jobs.
All the instances that are not leaders, stay inactive in a wait state and try to become the leader continuously.
When a new instance of the service is started, it is not set as a leader at startup time but instead, it starts the process to become one.
When an instance that is the leader for any issue stays unresponsive or is shut down, one of the other running instances becomes the leader.
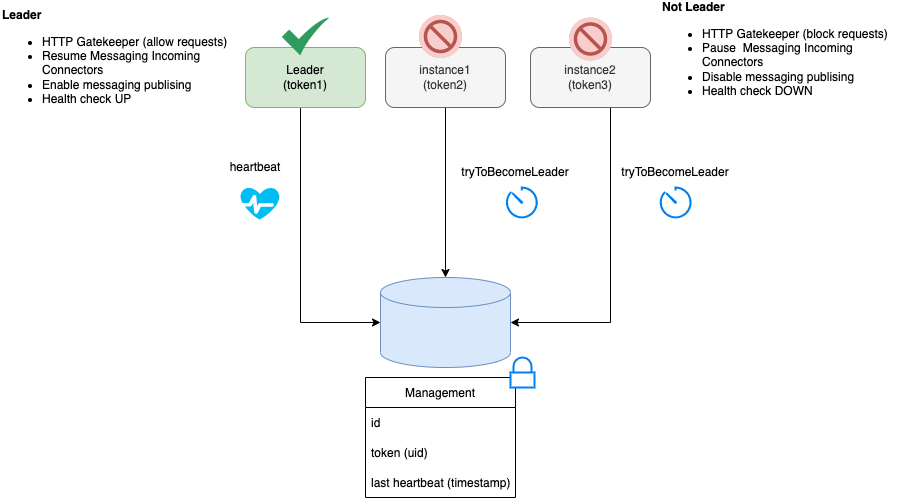
|
This leader election mechanism uses the underlying persistence backend, which currently is only supported in the PostgreSQL implementation. |
There is no need for any configuration to support this feature, the only requirement is to have the supported database with the data schema up-to-date as described in the Job Service PostgreSQL Configuration section.
In case the underlying persistence does not support this feature, you must guarantee that just one single instance of the Job Service is running at the same time.
Found an issue?
If you find an issue or any misleading information, please feel free to report it here. We really appreciate it!