Job Service
In Kogito Serverless Workflow architecture there is a dedicated supporting service that is responsible for controlling the execution of time-triggered actions, also known as jobs.
The job execution is a callback to the Kogito Serverless Workflow runtime application. This callback can be configured in different ways as described in the communication section.
Job Service configuration
All timer nodes that might be declared in a workflow, are handled by the job service, which is responsible for managing, scheduling, and firing all actions (jobs) to be executed in the workflows.
|
Suppose the workflow service is not configured to use the Job Service or there is no such service running. In that case, all timer-related actions use an embedded in-memory implementation of the Job Service, which should not be used in production, since when the application shutdown, all timers are lost, which in a serverless architecture is a very common behavior with the scale to zero approach. That said, the usage of in-memory Job Service can only be done for testing or development, but not for production. |
The main goal of the Job Service is to work with only active jobs. The Job Service tracks only the jobs that are scheduled and that need to be executed. When a job reaches a final state, the job is removed from the Job Service.
When configured in your environment, all the jobs information and status changes are sent to the Kogito Serverless Workflow Data
Index Service, where they can be indexed and made available by GraphQL queries.
|
Data index service and the support for jobs information will be available in future releases. |
Job Service persistence
An important configuration aspect of the Job Service is the persistence mechanism, where all job information is stored in a database that makes this information durable upon service restarts and guarantees no information is lost.
PostgreSQL
PostgreSQL is the recommended database to use with the Job Service. Additionally, it provides an initialization procedure that integrates Flyway for the database initialization. It automatically controls the database schema, in this way all tables are created by the service.
In case you need to externally control the database schema, you can check and apply the DDL scripts for the Job Service in the same way as described in Manually executing scripts guide.
You need to set the proper configuration parameters when starting the Job Service. The timeout showcase example shows how to run PostgreSQL as a Kubernetes deployment, but you can run it the way it fits in your environment, the important part is to set all the configuration parameters points to your running instance of PostgreSQL.
Job service leader election
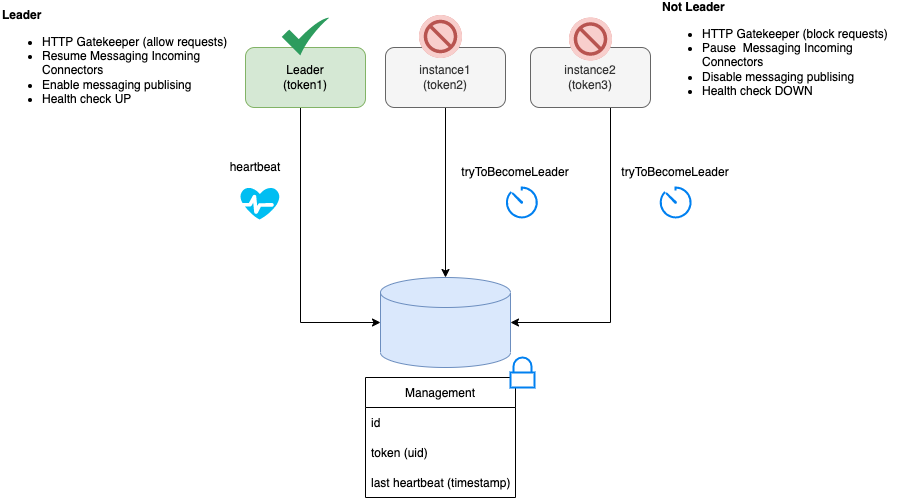
Currently, the Job Service works in a single instance manner where there should be just one active instance of the service.
To avoid issues when deploying the service in the cloud, where it is common to eventually have more than one instance deployed, the Job Service supports a leader instance election process. Only the instance that becomes the leader activates the external communication to receive and schedule jobs.
In all instances who are not leaders, stay inactive in a kind of wait state and try to become the leader continuously.
When a new instance of the service is started, it is not set as a leader at startup time but instead, it starts the process to become one.
When an instance that is the leader for any issue stays unresponsive or is shut down, one of the other running instances becomes the leader.
|
This leader election mechanism uses the underlying persistence backend, which currently is only supported in the PostgreSQL implementation. |
There is no need for any configuration to support this feature, the only requirement is to have the supported database with the data schema up-to-date as described in the PostgreSQL section.
In case the underlying persistence does not support this feature, you must guarantee that just one single instance of the Job Service is running at the same time. that just one single instance of the Job Service is running at the same time.
Job Service communication
|
The Job Service does not execute a job but triggers a callback that might be an HTTP request or a Cloud Event that is managed by the configured jobs addon in the workflow application. |
Knative Eventing
To configure the communication between the Job Service and the workflow runtime through the Knative eventing system, you must provide a set of configurations.
The Job Service configuration is accomplished through the deployment descriptor shown in the example.
Found an issue?
If you find an issue or any misleading information, please feel free to report it here. We really appreciate it!